



Hot Reviews
Trending AI products that everyone is talking about

The 5 Best AI App Builders in 2026
This article reviews the 5 best AI app builders in 2026, and explains how AI app makers simplify app development through prompts, no-code tools, and automation.

Unitree Introduces As2: A Lightweight Industrial Quadruped Robot Targeting a New Market Segment
On February 24, following the viral appearance of its humanoid robots performing martial arts at the Spring Festival Gala, Unitree Technology unveiled a new quadruped robot: the Unitree As2. This marks the company’s latest move in expanding its four-legged robotics portfolio.

The 6 Best Smart Speakers of 2026
Smart speakers have become essential gadgets in modern homes, blending high-quality audio with intelligent voice assistants. Whether you want hands-free control over music, smart lights, reminders, or everyday search queries, a good smart speaker makes your environment both more interactive and more convenient.

Eilik Robot: The Adorable Companion Robot You Didn’t Know You Needed
The Eilik Robot is a playful companion robot designed to express emotions and bring joy to kids and adults alike. In this review, we cover its features, price, pros and cons, user experience, and comparisons with Miko 3 and Vector to help you decide if it’s the right robot companion for you.

Aibo Robot Dog: Sony’s Companion That Blurs the Line Between Tech and Emotion
Discover the Aibo robot dog by Sony, a lifelike AI companion that blends technology with emotional interaction. From expressive design and adaptive personality to smart features, this Sony robot dog creates a unique bond with its owners, offering companionship, playfulness, and futuristic pet experience for tech lovers and families alike.

Enabot EBO: AI Guardian Robot That Blends Security, Companionship, and Fun
Discover the Enabot EBO, a mobile robot that blends home security, pet play, and emotional companionship. With live video, AI tracking, and expressive eyes, this ebo robot is designed to connect families and make technology feel alive.






Latest Reviews
Stay updated with our comprehensive analysis of the newest AI hardware and software releases.
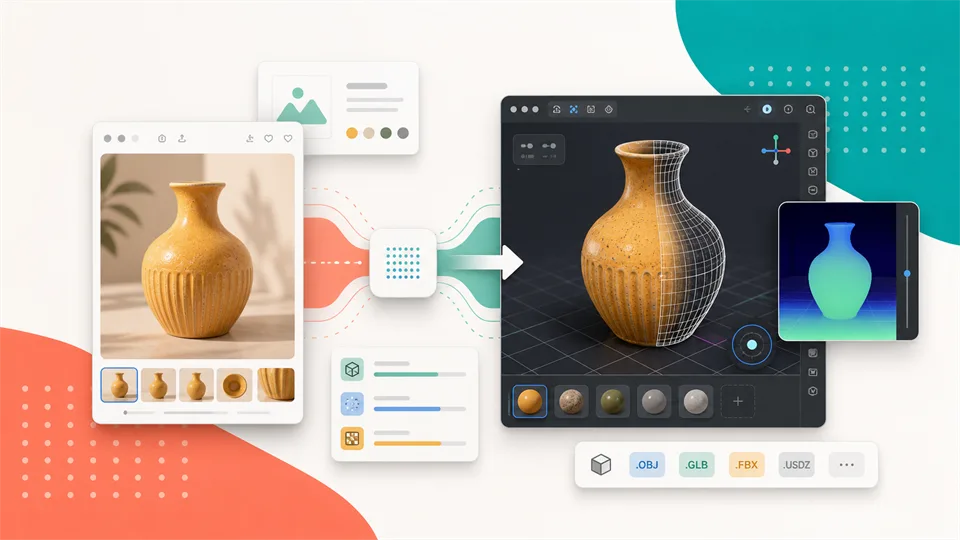
Best 5 Image to 3D Generators in 2026
Compare the best image to 3D tools for turning photos, sketches, product images, and concept art into usable 3D models.

Best 5 PDF Enhancers in 2026
Compare the best PDF enhancers for OCR, scanned PDF cleanup, readability, editing, compression, AI summaries, and document repair.

Best 5 Invoice Generators in 2026
Compare the best invoice generators for free invoices, online payments, branded templates, recurring billing, and small business invoicing.
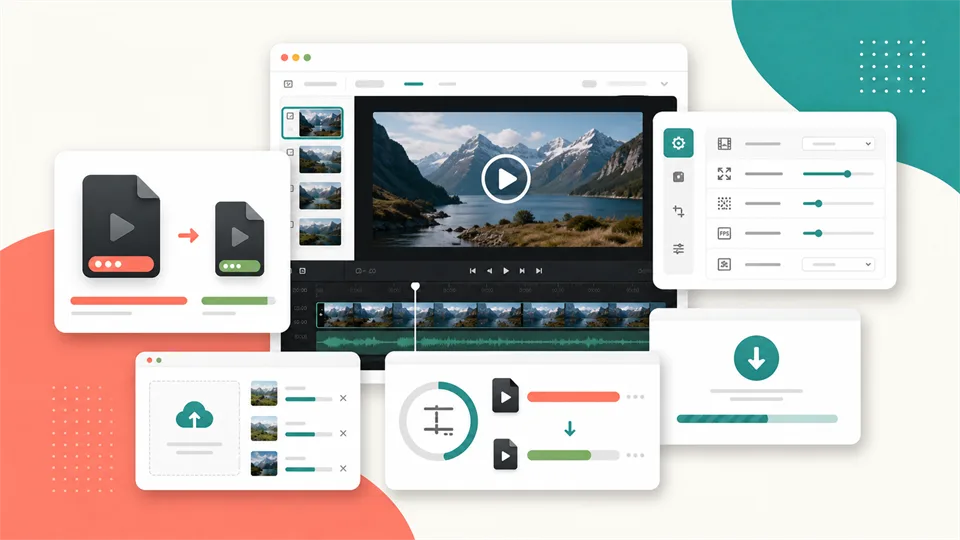
Best 6 Video Compressor Tools in 2026
Compare the best video compressor tools to reduce video size online, shrink MP4 files, control quality, and prepare clips for email or social media.
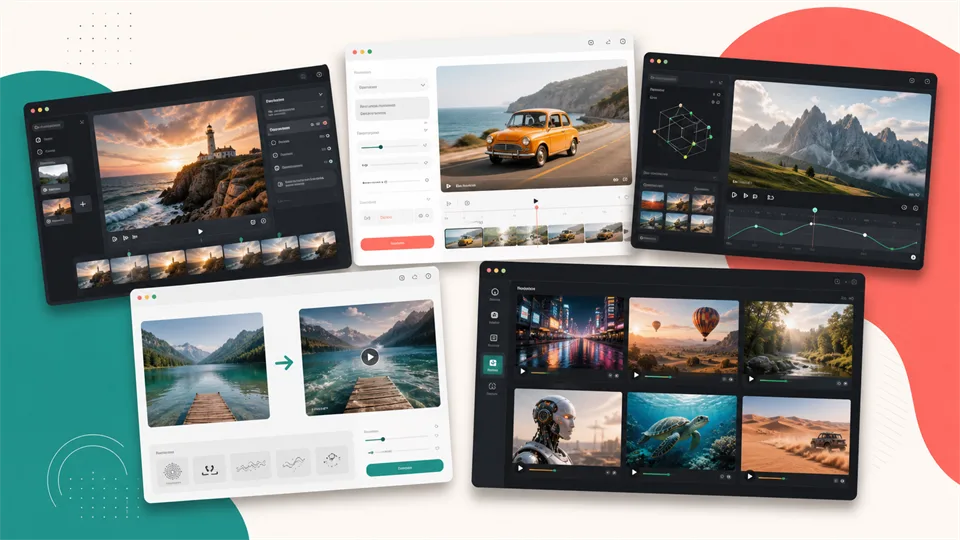
Best 5 Image to Video AI Tools in 2026
Compare the best image to video AI tools for animating photos, product shots, portraits, social clips, cinematic scenes, and brand-safe videos.
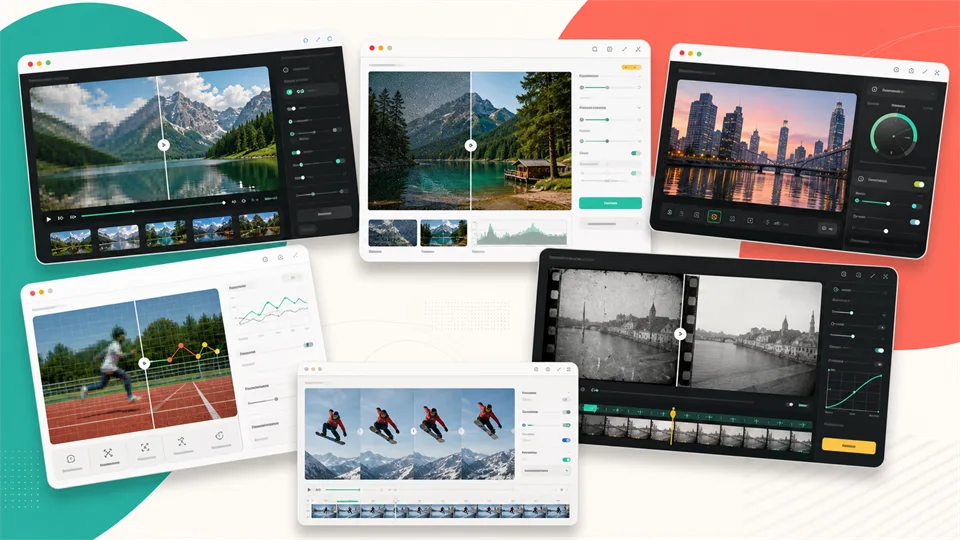
Best 5 Video Quality Enhancer Tools in 2026
Compare the best video quality enhancer tools for upscaling, denoising, sharpening, restoring old footage, fixing blur, and improving clips.

5 Best Wallpaper Maker Tools in 2026
Compare 5 top Wallpaper Maker tools for phone, desktop, branded, aesthetic, and AI-generated backgrounds, with pros, cons, and best use cases.

5 Best Collage Maker Tools in 2026
Compare 5 top collage maker tools for templates, social posts, large photo grids, branded designs, and one-click layouts, with pros and cons.
AI News
Stay updated with the latest developments and breakthroughs in global artificial intelligence
Startup backed by the world's largest battery maker just launched a supercheap mini PC that competes with Nvidia's $5000 AI DGX Spark PC
TechCrunch Mobility: Two roads diverged — for robotaxis
Minnesotas nudification ban takes effect after judge rejects xAIs bid to pause it
UK tests robot boat that can fly its own wired drone even in 14ft waves and stay at sea for weeks
One dashboard, 20+ AI models — get ChatGPT, Claude, Gemini, and more for $79
Half of adults admit they would publish work created mainly by AI and not say so — despite believing other people should do just that
AI financial advice is surprisingly good, especially if you ask right questions
Seedance 2.5
China outs Nvidia-powered AS2-W quad-wheel 'robot wolf', just weeks after its armed version surfaced in joint military drills in Mongolia
The Samsung Galaxy Watch Ultra 2 comes with a free $100 gift card this weekend
Google News is just Forrest Gump’s shrimp boat now
Judge denies xAI’s request to block Minnesota ban on ‘nudify’ apps
'A disk in a planet-scale computer': Meta has so many expensive GPUs that it's buying SSDs to kill idle time
AI in Formula One: Competitive advantage is all about the human in the loop
I asked ChatGPT and Siri AI to build me a workout plan — and there was only one winner
Pre-order the Samsung Galaxy Watch 9 this weekend and get a free $50 Amazon gift card
Is AI reasoning right for the wrong reasons?
Pentagon is looking for drone bombers, but don't expect a B52 replacement, as they'd carry only an 18 lb payload
Seagate reveals more on its 50TB HDD plans — but looks like we'll still have a long wait to buy one
Reddit keeps its strange DMCA fight over Google search results alive















Latest Tutorials
Stay updated with our newest guides and tutorials on AI tools and technologies

Best AI Tarot Websites for Online Tarot Readings

Best PDF Compressor and PDF Merger Tools
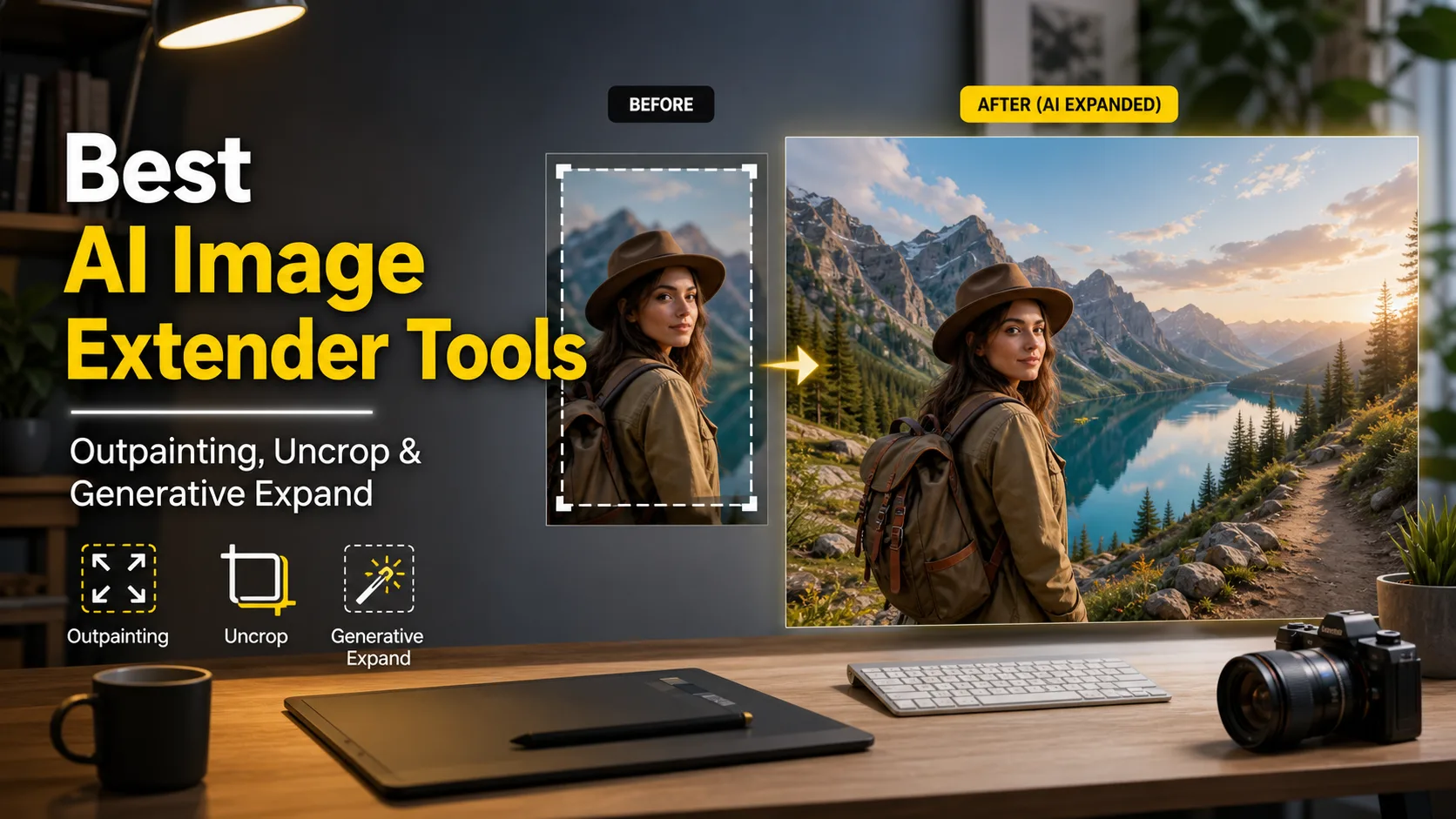
Best AI Image Extender and Outpainting Tools


